Over on Stack Exchange, someone asked why their transaction log was growing very fast during a full backup. An interesting tidbit to this question is that the database is in SIMPLE recovery — so the log should stay tiny, right?
Wrong. While taking a full backup of the database, SQL Server is unable to reuse the transaction log for the duration of the backup, even if the database is in SIMPLE recovery. If your database is very busy, or backups take a long period of time, this can require a large transaction log, even if the database is in SIMPLE recovery.
Why does SQL Server need to do this?
Think of the database as a bookshelf containing a set of encyclopedias, and each table is a book in that set. SQL Server is the librarian. The librarian needs to make a copy of the full set so she has a backup copy.
The librarian (SQL Server) starts copying books (data pages) at one end of the shelf (database), and makes it’s way to the far end. This takes time. If the data within the books is changing (ie, database transactions), getting a consistent (that’s the “C” in ACID) snapshot becomes a challenge.
Now think about the following sequence of events as the librarian makes her copy of the data.
The librarian copies books A & B:
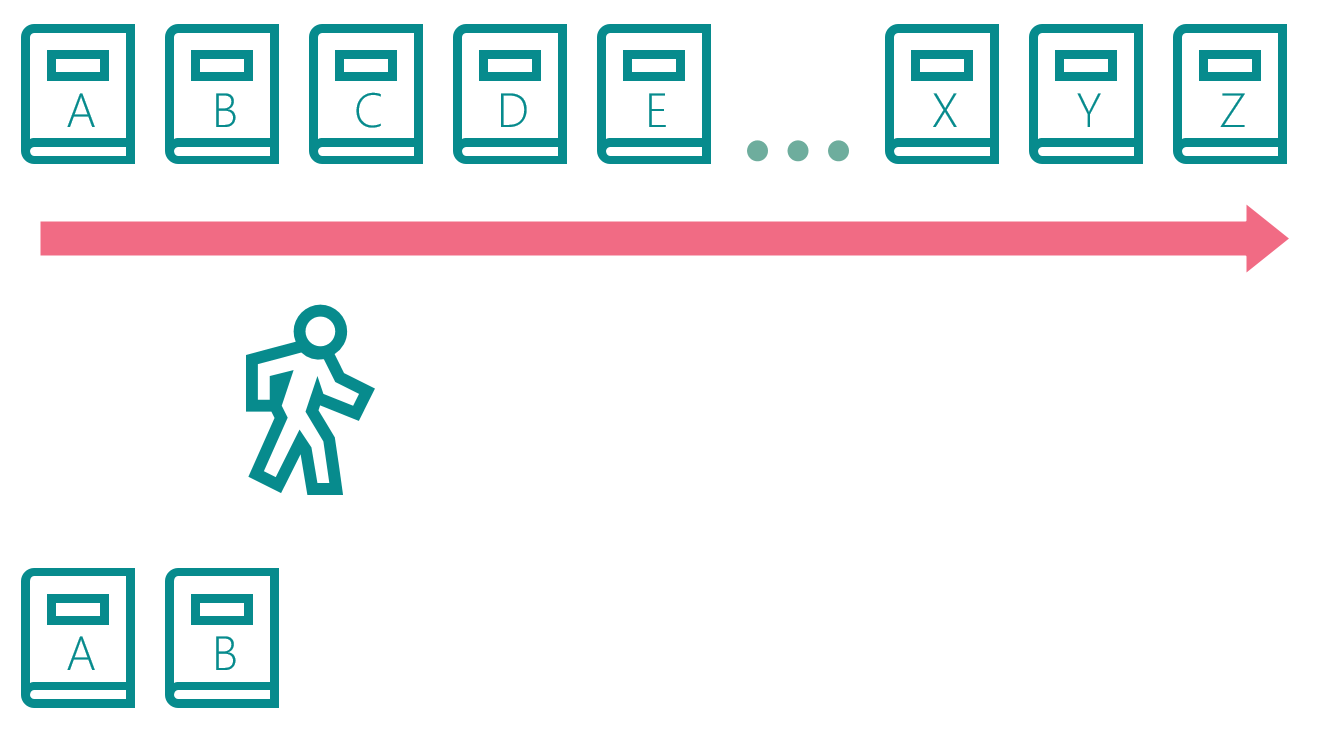
Books A & D are updated:

The librarian copies books C & D:
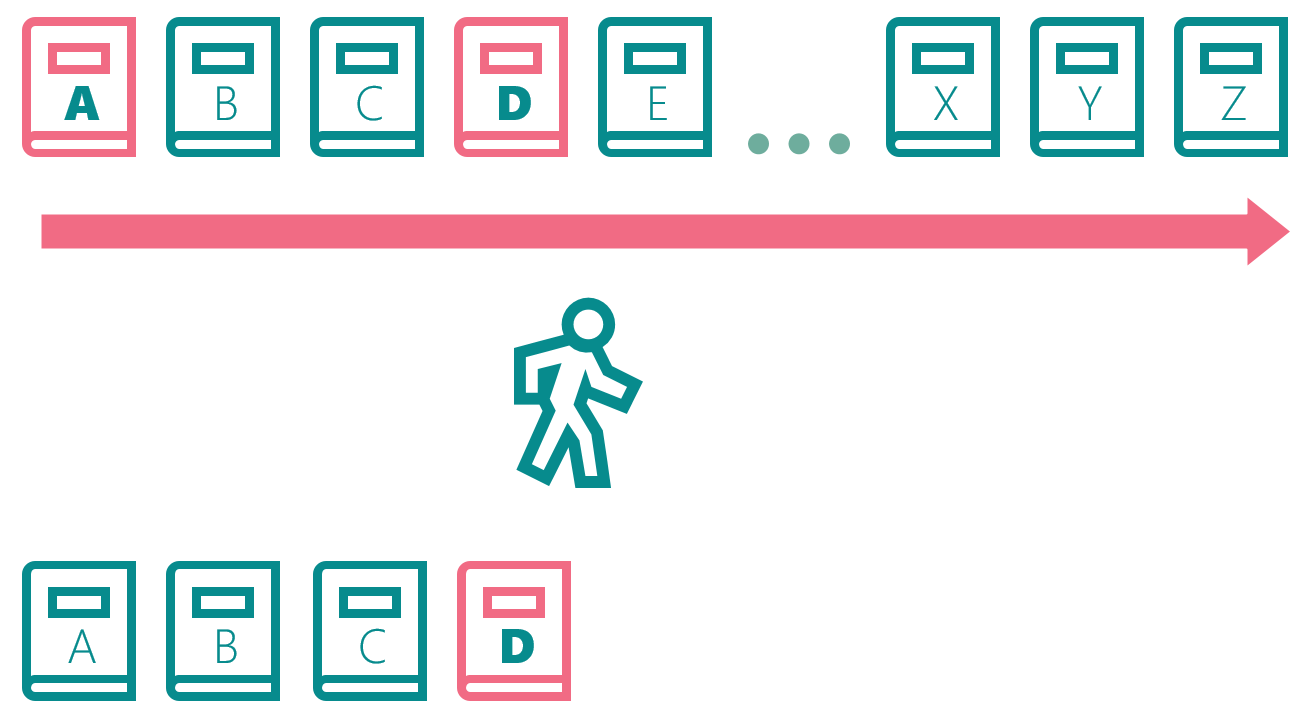
Books D, X, Y, Z are updated:
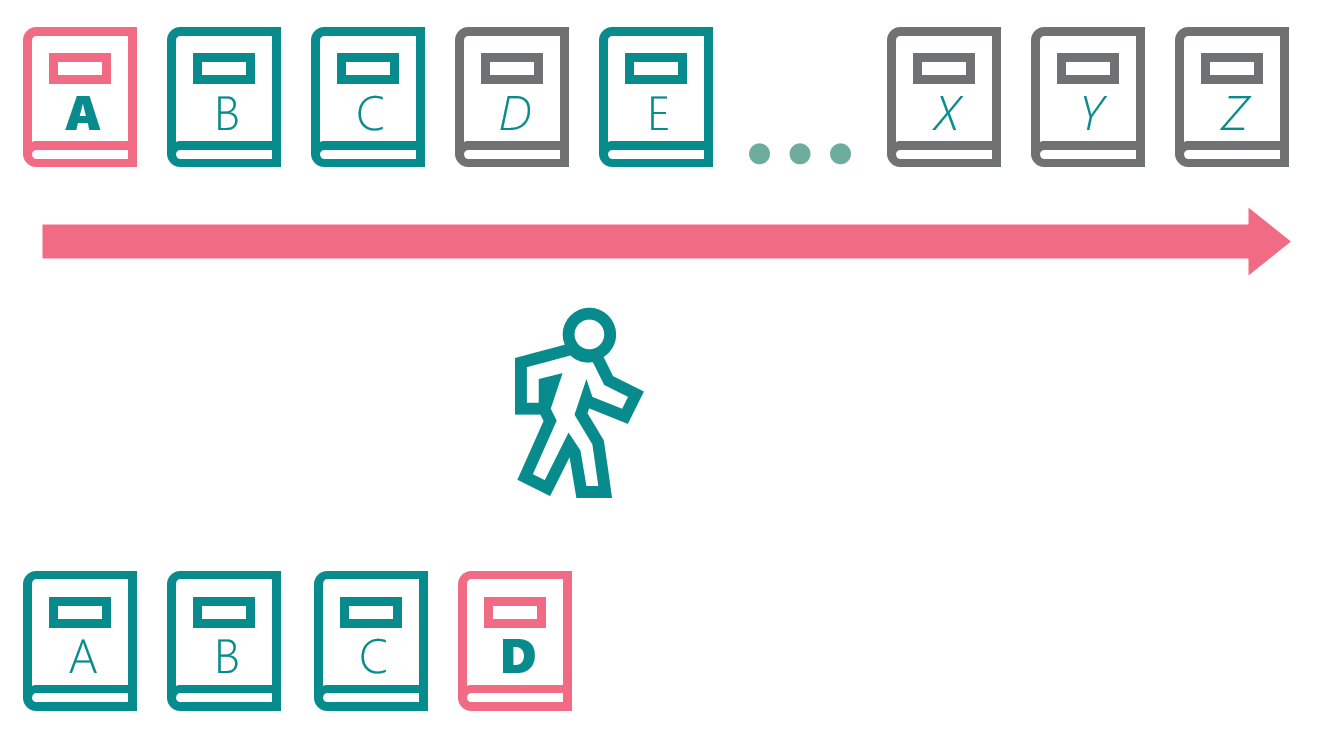
The librarian copies books E-Z. The backup is complete:
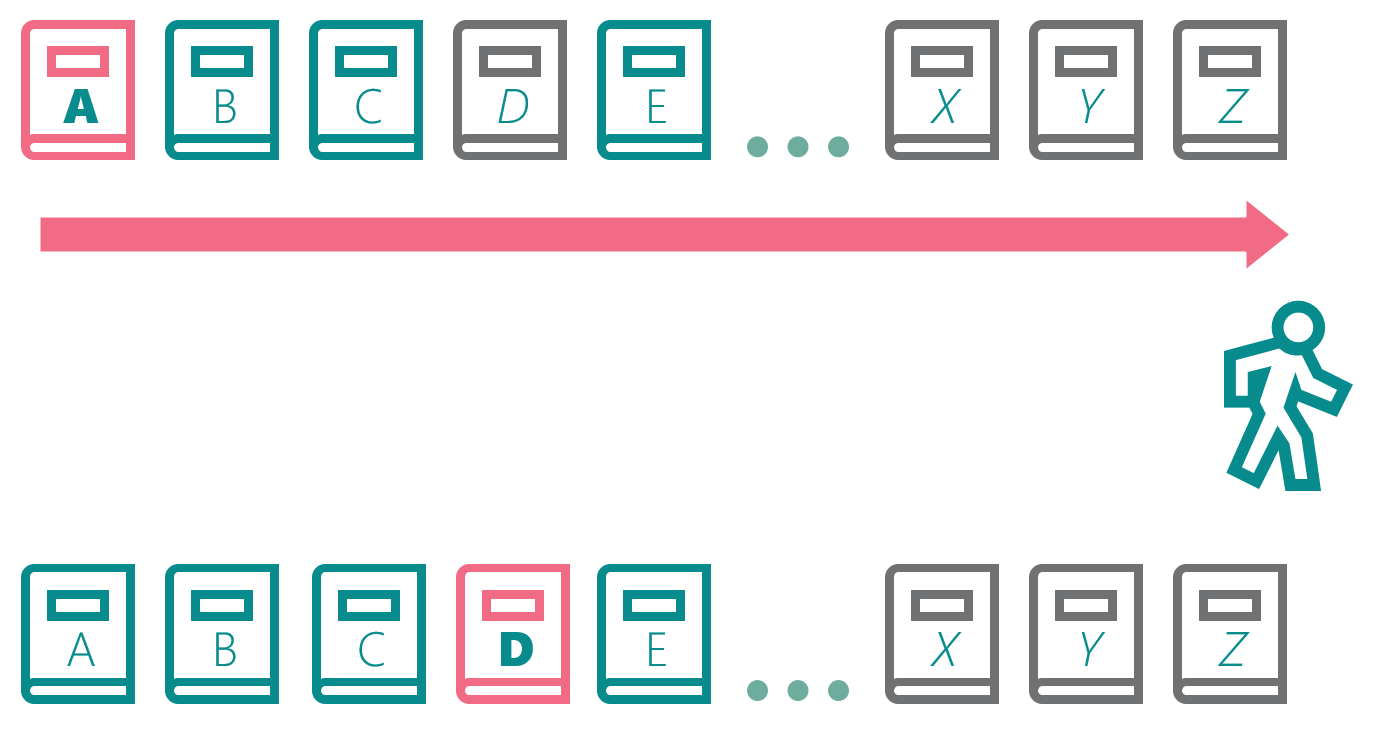
The librarian’s backup is not consistent. It has some of the old books, some of the updated books, but it doesn’t correspond to any specific point in time. During the time the librarian was making her copies, there were three specific versions of the books. There was (1) the initial starting state, (2) the state after the first update, and (3) the state after the second update. Because of the sequence of events, the librarian’s backup doesn’t match any of those states. Instead, it’s a mash-up of books from different versions.
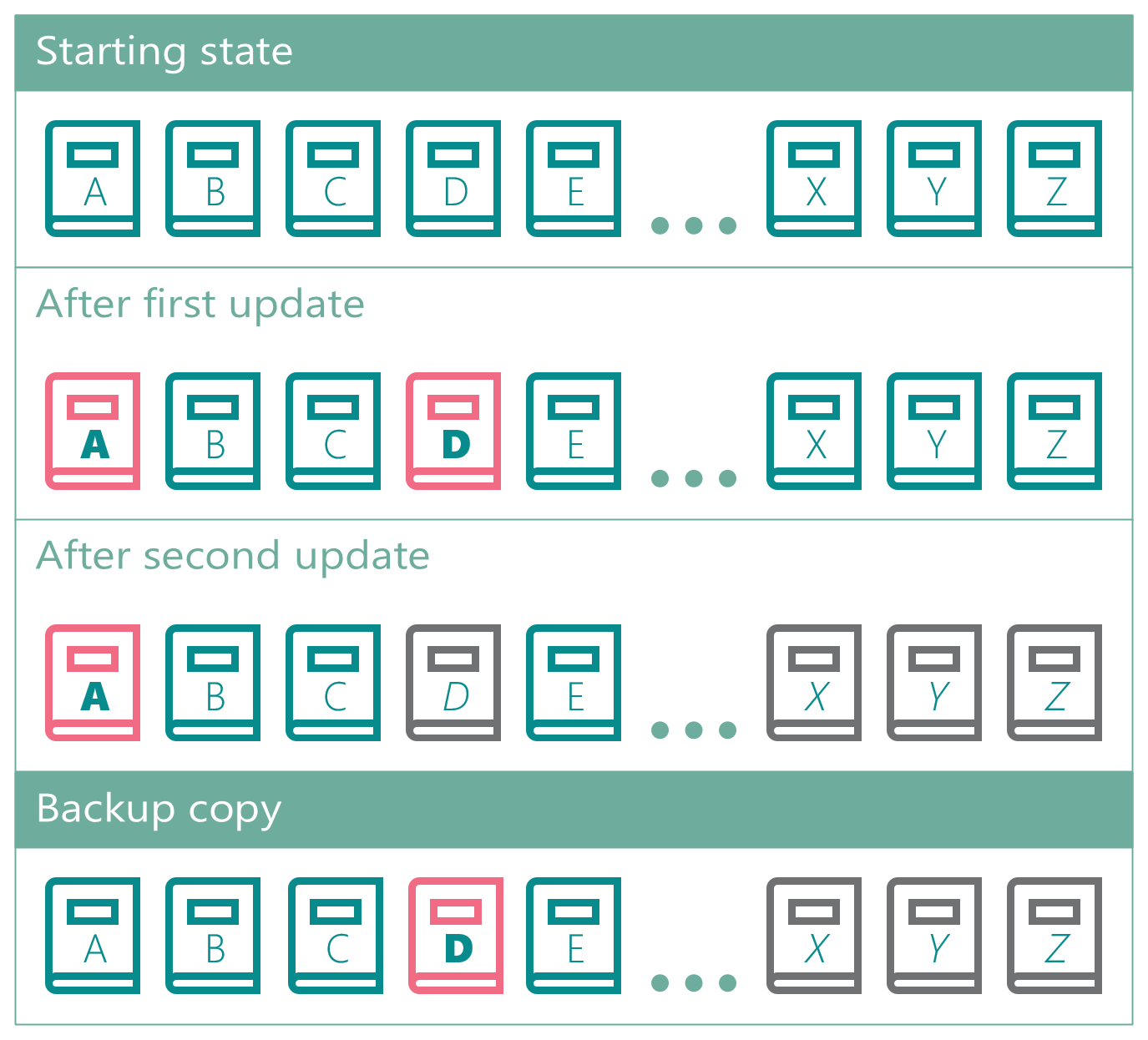
In order for the data to be consistent, the librarian could keep track of what changed during her copy task, then roll forward those changes on her backup copy.
It might be OK for the librarian to have an inconsistent backup, but it’s not OK for SQL Server to have an inconsistent backup. SQL Server’s backups must be consistent to a single point in time.
How do you achieve consistency?
When SQL Server begins backing up data pages, it also starts keeping track of transactions, via the transaction log. After it has backed up the last data page, it then also backs up all of the transactions that occurred during the data backup. Upon restore, it will then roll those transactions forward or backward, as necessary, to ensure a consistent image is restored.
In our librarian metaphor, she would keep an activity log, which would include the changes to books A and D from the first update, then also the changes to D, X, Y, and Z from the second update. She would not “fix” the data within the backup, but simply store those update details along with her mashed-up copy. In the unlikely event she had to recreate the books (ie, a restore), then she would go back and spend the effort to piece it back together. During that restore process, she would look at the first transaction and see that her copy of Book A in her backup was too old, but Book D already had the update, and she would roll forward the update to Book A. Next, she would process the second update and see that Books X, Y, and Z had the updates, but D still needed this second update, and she would roll forward that second update to Book D. At this point, she would have successfully reconstructed an image that is consistent to the time the backup completed.

Backing up busy databases
If you have a database that is 7TB, and takes several hours to back up, the transaction log for this database must be large enough to accommodate several hours worth of transactions–even under the SIMPLE recovery model. Depending on the amount and type of activity, the amount of transaction log needed could very quite a bit. A very busy database that is in simple recovery mode might require a very large transaction log in order to accommodate backups.
To reduce the amount of transaction log needed, you can either try to make your backup go faster, or take your backups during a time of reduced write activity, or both.
You should not play whack-a-mole, constantly shrinking your log only to have it grow again the next time you take a full backup. Allowing the log to auto-grow many times during the backup will likely result in having too many VLFs, which will ultimately slow down your restore performance. Once you have an idea of how large your transaction log needs to be, explicitly grow your log to be that large and leave it there.
Now, go to your local library and thank your librarian for helping you understand SQL Server just a little bit better.
B0C2
Very good explanation Andy. Well done! Tim