This Q&A was previously posted on the Stack Exchange Network of websites.
This content is licensed under the Creative Commmons Attribution-Sharealike (CC BY-SA) license. As the author of these answers, this archive serves as a canonical location for permalinks, which will outlive Stack Overflow. See all my answers by looking at the Stack Exchange post category.
Is it possible to re-use a query plan from the plan cache from one database in another database?

Question
For example, if I hit the sys dynamic views to select a specific query plan, am I able to insert that query plan into another database’s plan cache, that runs the same exact query? (I know the query is hashed and compared to determine when to generate a new plan, so in my example I would ensure the query truly is exactly the same character by character.)
asked 2019-11-01 by J.D.
Answer
No
Ok, so that’s the answer to your question, but you probably want to know why.
Ok, so why not?
Different databases might have different data, and thus need different plans.
Say you restore the WideWorldImporters database to the same server TWICE (Let’s call it WWI_1 and WWI_2). You’ve got two identical databases. SQL Server could possibly create one plan and use it in queries for both databases.
But the problem is, the instant these two databases come online, thier “sameness” forks. They can be altered independently. Even if they maintain the same schema, their data can change independently. Thus, SQL Server must consider the databases independently when compiling plans. WWI_1 could have different statistics from WWI_2, which could result in different plans. In order for SQL Server to use the same plan for both databases, SQL Server would need to keep track of the differences after forking–which would be more complicated & more expensive than just compiling/maintaining separate plans.
Let’s take a real-world example
Let’s pretend you are a software company, and host software for your customers. Every customer gets their own database. In your hosting environment, you might have hundreds of databases on every server, where every database has identical schema, but data unique to each client.
One client has a customer base with 95% California clients. Querying the address table for all customers in California would result in a table scan.
-- For CustomerA this query returns 95% of the table, so it scans SELECT CustomerID FROM dbo.Addresses WHERE StateCode = 'CA';
A different client has a customer base that is evenly distributed across every US state, and has a significant international business as well. A comparatively small percentage of clients are from California. In this case, querying the address table for all customers in California would result in a table seek.
-- For CustomerB this query returns <1% of the table, so it seeks SELECT CustomerID FROM dbo.Addresses WHERE StateCode = 'CA';
Identical queries, on databases with identical schema, with radically different plans due to different statistics. Even if these two databases were both originally restored from the same source backup, SQL Server will need to compile separate plans.
It’s not enough that the two queries are 100% identical, and the schema is 100% identical. A reused plan based only on those criteria could be very wrong–and thus SQL Server won’t do it.
Could you do it if you really wanted to?
Uh….kind of.
Let’s use the same “you are a software company, and host software for your customers” example. You want to force the same plan across every hosted database, regardless of what SQL Server wants to do. You could use a plan guide and apply the same guidance to every single database on the server. This isn’t quite the same as “insert [one] query plan into another database’s plan cache”… but it would be virtually the same thing.
What about a totally trivial plan?
Something like SELECT COUNT(*) FROM dbo.SomeTable would be simple enough to use the same plan on both two databases, right? No, not even then!
Let’s create an example:
- Create a sample database
- Create a table & populate it with some data
- Note the table has a Clustered PK & a non-clustered index
- Backup & restore a second copy to the same server
Here’s some code to do that:
CREATE DATABASE Sample1;
GO
USE Sample1
GO
CREATE TABLE dbo.SomeTable (
SomeID int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
StuffType int,
OtherStuff varchar(100),
INDEX OtherStuff(OtherStuff)
);
GO
SET NOCOUNT ON;
INSERT INTO dbo.SomeTable (StuffType,OtherStuff)
SELECT object_id%50,
name
FROM sys.objects;
GO 1000
BACKUP DATABASE Sample1 TO DISK = '/var/opt/mssql/data/Sample1.bak' WITH INIT;
RESTORE DATABASE Sample2 FROM DISK = '/var/opt/mssql/data/Sample1.bak'
WITH MOVE 'Sample1' TO '/var/opt/mssql/data/Sample2.mdf',
MOVE 'Sample1_log' TO '/var/opt/mssql/data/Sample2_log.ldf';
Now, let’s do that COUNT(*) query. Same plan on both? Yes! On my laptop, it’s performing the count by scanning the clustered PK
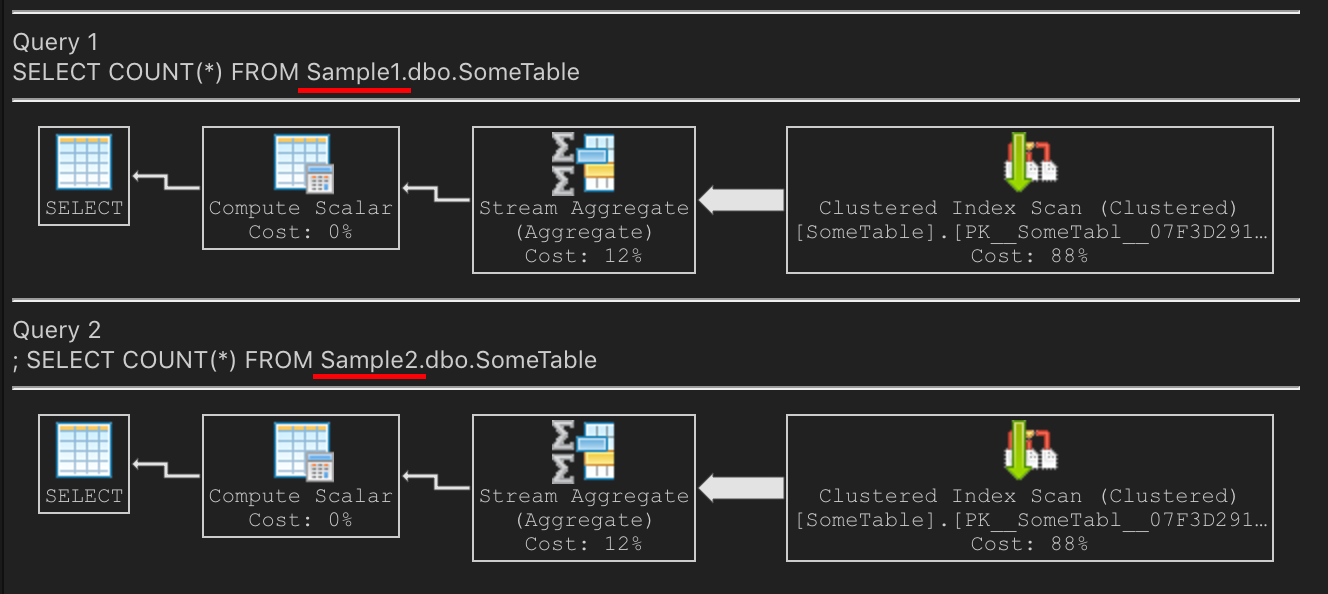
SQL Server is choosing to scan the PK because it’s smaller. The non-clustered index is larger because it’s highly fragmented.
Now index maintenance happens on the Sample1 database (but not Sample2). Someone rebuilds the indexes on dbo.SomeTable:
ALTER INDEX ALL ON Sample1.dbo.SomeTable REBUILD;
How does that affect the query plan?
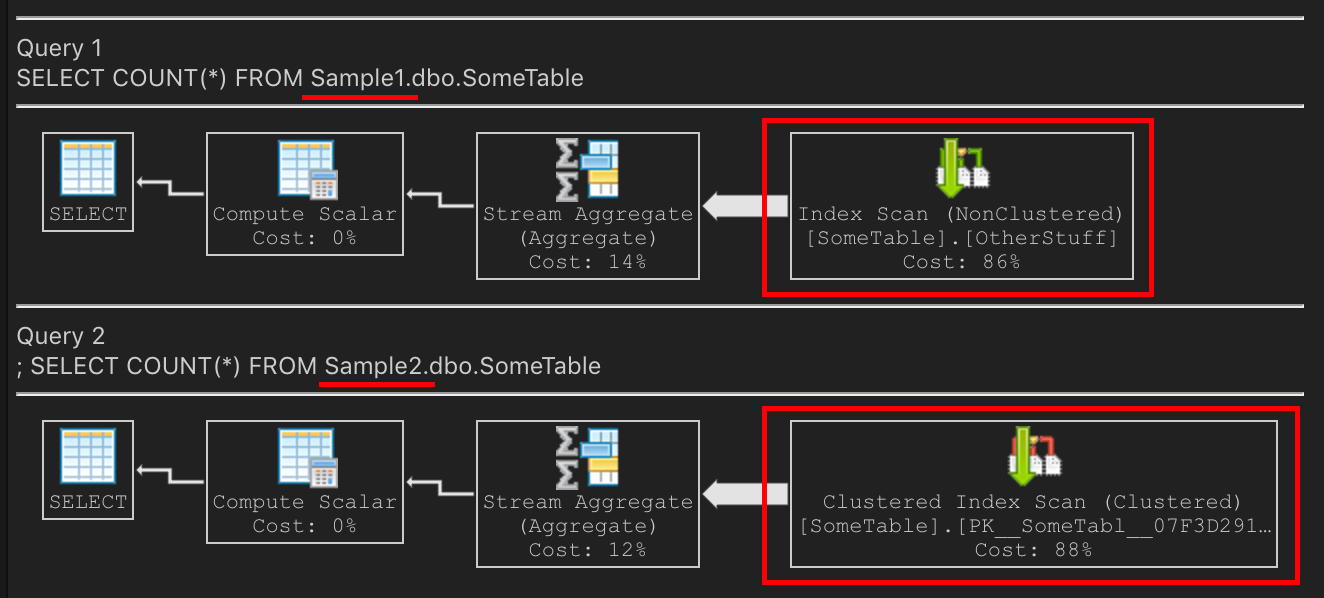
On Sample1, the non-clustered index is now nice & compact. It is smaller than the PK. Scanning the non-clustered index will be the right choice on `Sample1 because it’s smaller, fewer IOs, and will be faster.
On Sample2, scanning the PK is the right choice, because it’s smaller, fewer IOs, and thus faster.
Identical schemas with identical data, with the second forked from a recent backup of the first. Both of these queries have different execution plans, but both also have the best query plan for their scenario.
answered 2019-11-04 by Andy Mallon