SQL Server supports two kinds of data compression on rowstore data. Columnstore compression is for a different day. You can compress heaps, clustered indexes (on both tables and views), and nonclustered indexes (on both tables and views).
Compression requirements
Data compression is available in SQL Server 2008 & newer. It was introduced as an Enterprise Edition feature–if you were using Standard Edition or Express, then you were out of luck. Starting with SQL Server 2016 SP1 (thus all currently-supported versions), data compression is available across all Editions. There are benefits & costs to using data compression–as with anything, make sure you understand it before you implement it.
How page compression saves space
You can think of page compression as doing data deduplication within a page. If there is some value repeated in multiple spots on a page, then page compression can store the repetitive value only once, and save some space.
Page compression is actually a process that combines three different compression algorithms into a bigger algorithm. Page compression applies these three algorithms in order:
1) Row compression
2) Prefix compression
3) Dictionary compression
Yes, “Row compression” is that other type of data compression that I’ve already blogged about. Page compression just builds on top of row compression by doing more work. In this post, I’ll talk more about prefix & dictionary compression.
As with most things, Books Online has some good information. The article on Page Compression Implementation has good information, but the example is hard to understand. I’m going to step through that same example in extreme detail–hopefully doing a better job than BOL at explaining the details.
Prefix compression
Pages aren’t actually formatted like spreadsheets, but in these graphics it is. In these images, each row is a row, each column is a column.
We start with a simple data page. For the sake of argument, we’re going to say that row compression has already been applied to this page.
I’m also going to point out that this example uses all text values, but page compression works just as well with non-text datatypes. If you replace ABCD with 1234, the actual algorithm stays exactly the same.

Identify prefix values
For each column of data, we need to identify a single prefix value that we can use to reduce storage for this page. Remember, this algorithm is scoped to only look at this one page–every page gets it’s own set of prefixes. That means there is one prefix per column per page.
As the name suggests, prefix compression is applied to the START of the value. It will also do partial matches. The ideal prefix to select is a long value where the first bytes match many other values in that column, on that page.
Highlighted in green are the prefix values that have been identified for this page:

Write the prefix values to the CI structure
The next step is to create a row in the Compression Information structure, which is written after the page header. That row contains all the prefixes that we’ve identified:
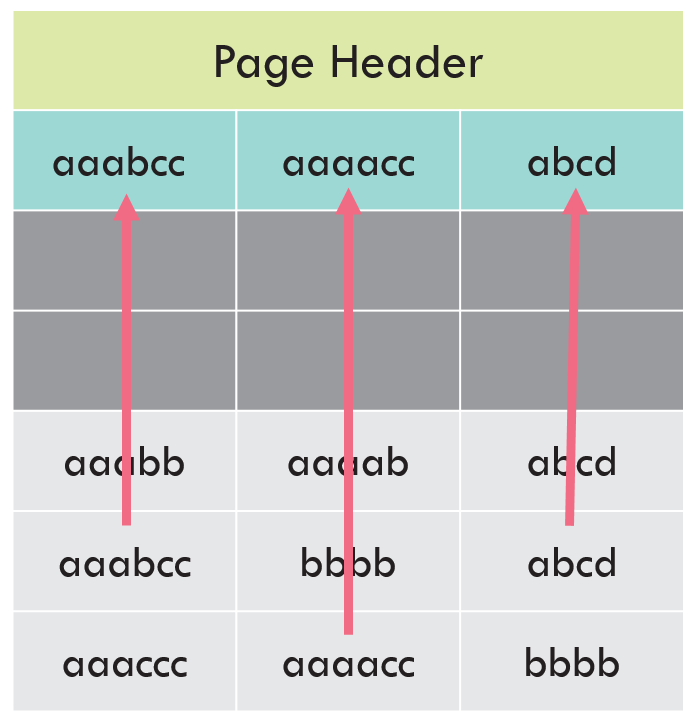
Point to the CI structure from the row data
And finally, we replace the data on each row with pointers to the prefix, any time there’s a match. The prefix matching is done for the data within that column, on that page.
Notice that some values have been completely replaced with the pointer–that’s because the prefix matches the full value. When there is a partial match, the pointer indicates how many characters (bytes) matched. If there’s no match, there is still overhead to indicate “this doesn’t match the prefix.”
Dictionary compression
Dictionary compression works in a similar way to prefix compression, except it applies to all values across all columns on the page.
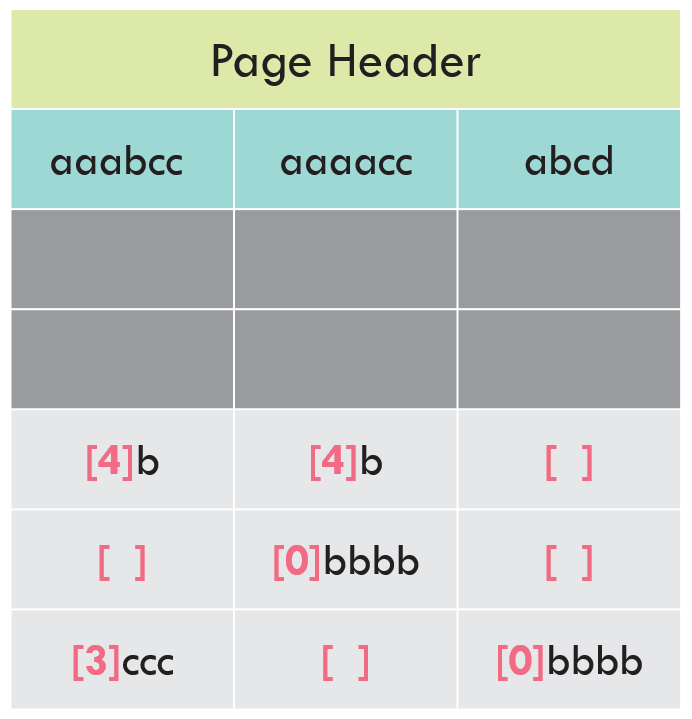
Identify dictionary values
Dictionary compression looks for values that get repeated multiple times on the page. This search happens on the prefix-compressed values, not the original values.
In this example “aaabb” (3 a’s + 3 b’s) in Col1 was prefix-compressed to “[4]b”. In Col2, “aaaab” (4 a’s plus 1 b) was prefix-compressed to “[4]b”. The original values were different, but the prefix-compressed values match. Dictionary compression will identify these as matches!

Write the dictionary values to the CI structure
These dictionary compression values are now copied up to the CI structure. (See the parallels to the process for prefix compression?)
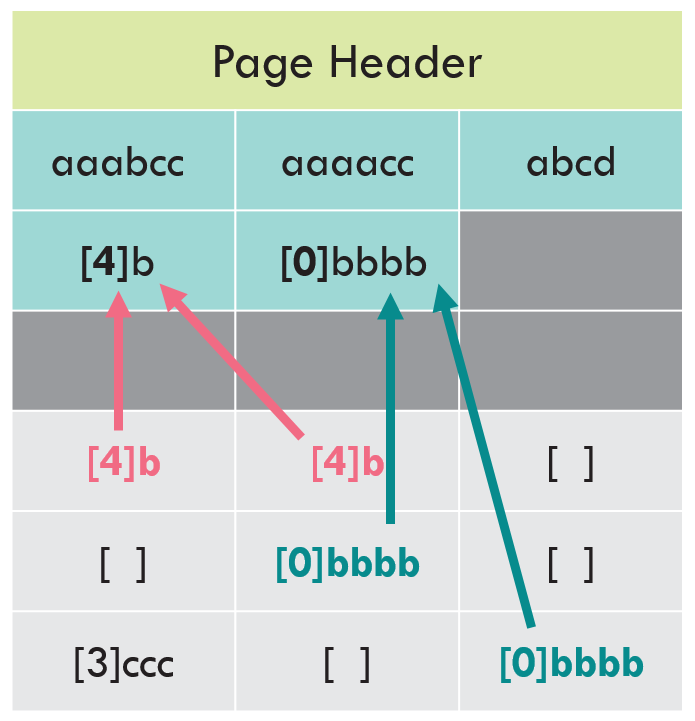
Point to the CI structure from the row data
The values in the row data are replaced with pointers to the dictionary in the CI structure. The dictionary values are treated as a zero-based index. So “[4]b” is the 0th value, and “[0]bbbb” is the 1st value. In Europe, you enter a building on the Ground floor and walk upstairs to the first floor. This is the same thing.

That’s it. We’re done. Take a look at the page before and after we applied these compression algorithms.
Before and after
You can get the sense that we saved room, but it’s hard to say exactly how much. If we count characters, we’ll see there are fewer characters used in the page-compressed page.
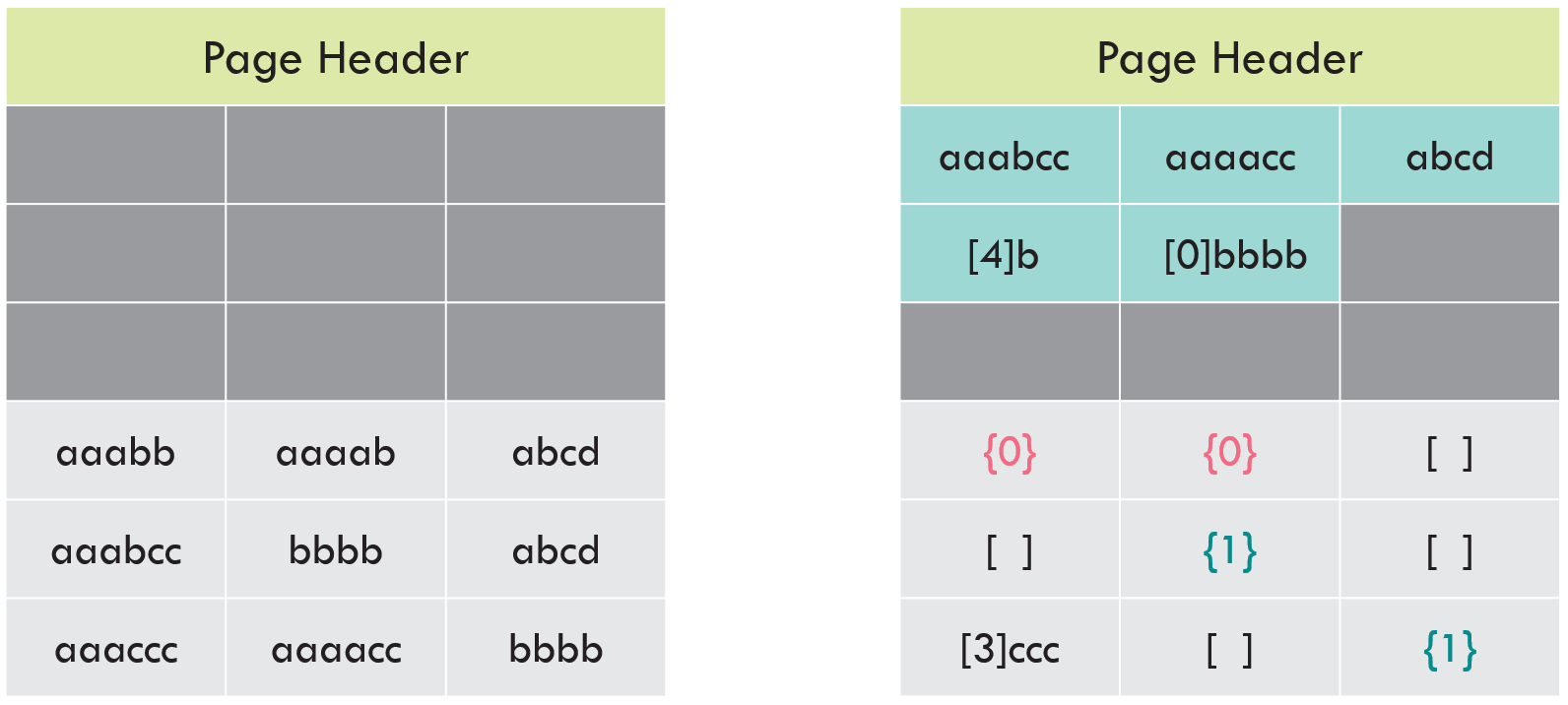
Remember how I mentioned that pages aren’t actually written in a tabular, spreadsheet-like format? In reality, everything is squished together so that the page is information-dense. Lets represent that by using commas as field delimiters, and semicolons as row delimiters.
Without page compression, three rows used about 30% of the page. We’d (probably) fit about 6 more rows on the page before it was full.
With page compression, we’re still using about 30% of this page. However, the CI structure is using about 15% of the page, and the three rows are using about 15% of the page. We’d (probably) fit about 12 more rows on the page before it was full.

There’s a catch
In this example, the data compressed really nicely. The density of data increased from 9 rows per page to 15 rows per page.
That’s not always the case. Sometimes, page compression won’t be able to save a significant amount of space. What that happens, SQL Server will still perform page compression, determine that the specific page did not compress well, then discard the work performed with prefix and dictionary compression…falling back to just the row-compressed page. It does all the work for page compression, but only write the row-compressed values. When this happens, you’re burning CPU cycles for no value.
You can use sys.dm_db_index_physical_stats to monitor if you have page-compressed indexes that are not benefiting from page compression.
SELECT DbName = db_name(database_id)
,TableName = object_name(object_id,database_id)
,IndexID = index_id
,IndexType = index_type_desc
,AllocUnitType = alloc_unit_type_desc
,IndexSizeKB = page_count * 8
,CompressedPages = compressed_page_count
,UncompressedPages = page_count - compressed_page_count
,AvgRecordSizeBytes = avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(db_id('MyDb'),NULL,NULL,NULL,
'Detailed') -- Have to use Detailed mode to get compression info
WHERE index_level = 0 --Only the leaf level of the index
ORDER BY compressed_page_count DESC,
page_count DESC;
Conclusion
Just like row compression, you’ll find that page compression will often, but not always, save you space. Additionally, you may find that for certain indexes page compression falls back to row compression. When this happens, there is no added benenfit despite added cost–in these cases, you should use row compression instead. You need to know your data, know your schema, and do testing. Watch for those scenarios where page compression is not providing net benefit.